파이썬 과학 처리 패키지 NumPy
행렬과 매트릭스를 코드로 어떻게 표현할 것인가?
방정식의 각 변수의 계수와, 상수를 변환한다.
하지만 이렇게 생성된 매트릭스를 어떻게 계산할 것인가? 심지어 파이썬은 인터프리터 언어이기 때문에 느린 편인데 Matrix size가 커지면 속도가 느려지는게 눈에 보일텐데?
이에 대한 해결책으로 NumPy가 제시된다.
NumPy: 일반 리스트에 비해 빠르고, 메모리 효율적
반복문 없이 데이터 배열에 대한 처리를 지원
선형대수와 관련된 다양한 기능을 제공함
C,C++,포트란 등의 언어와 통합 가능
왜 빠른가? C기반의 라이브러리이기 때문
그렇기 때문에 windows 환경에선 conda로 패키지 관리 필요
jupyter 등을 설치한 상태에서는 추가 설치 필요없음
import numpy as np
numpy의 호출방법
np.array([], 자료형) 을 통해서 배열 생성 가능
한개의 타입만 지정 가능하다. (list와 가장 큰 차이)
array의 rank에 따라
0-scalar
1-vector
2-metrix
n- n-tensor
로 분류된다.
np.array(matrix, int).shape
하면 array의 크기가 나온다.
가장 큰 범위 부터 읽으면 된다.

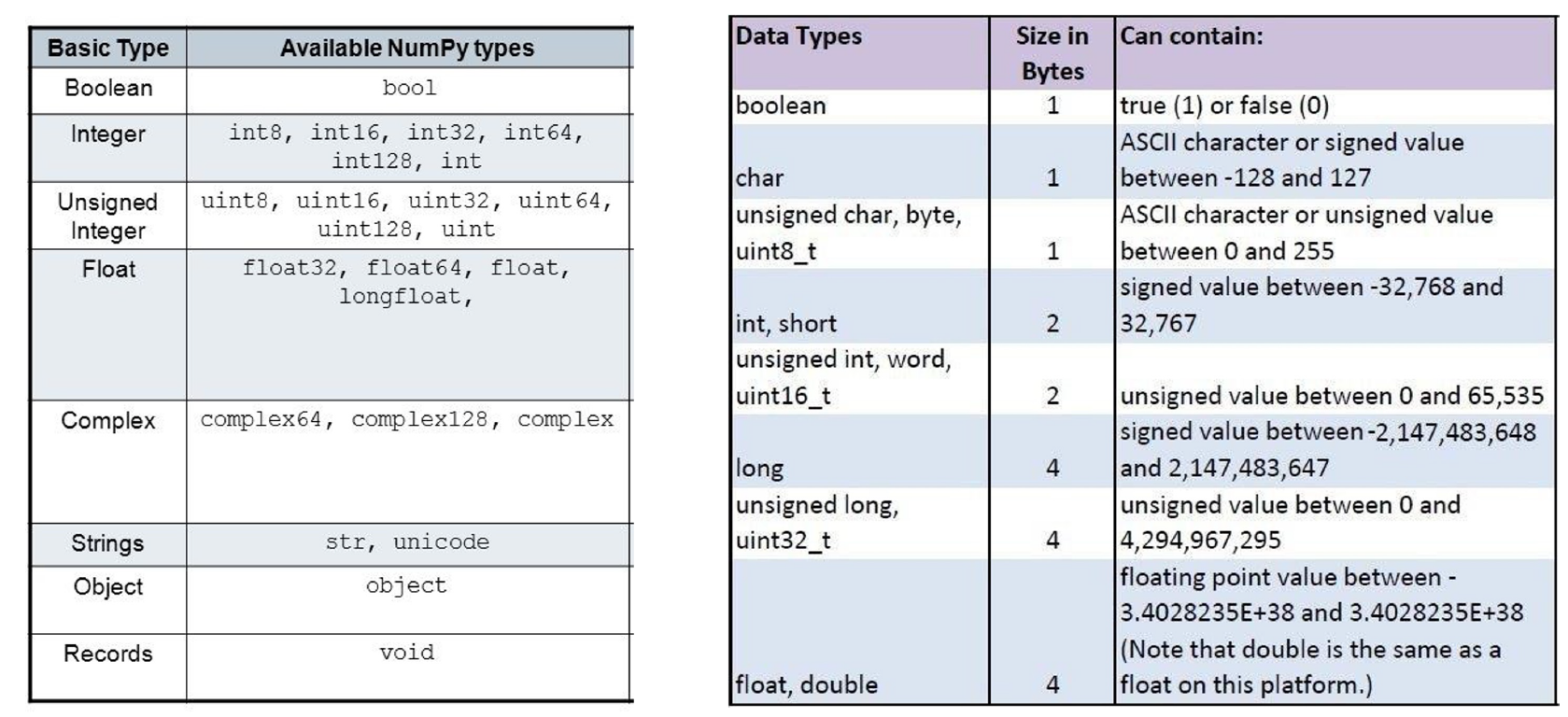
이거는 크게 3덩이, 세부적으로 4종으로 나뉘어져있다.
아래는 np.array에서 설정해줄 수 있는 dtype이다. 다만... 종류가 너무 많으니 int32가 default dtype으로 설정되어있다는 것을 인지하자!
np.array().nbytes = ndarray object 메모리 크기를 반환한다.
np.array().reshape(x,y,...) = array의 shape를 (x,y)로 변경한다. elements의 개수는 그대로 유지되어야 한다.
faltten = 다차원 array를 1차원으로 변경
np.array 배열은 이차원 배열에서 [x,y]로 표기 [x][y]도 가능하다. 차원이 많아지면 반복표현이 많아져서 이렇게 한걸지도?
slicing method 파이썬 list와 동일
[::x] = x칸 간격으로 선택
np.arange(n) : 0부터 n-1까지 array 생성
실제 range처럼 np.arange(start, end, step) 이런식으로도 사용가능
np.zeros(shape, dtype, order)
기본은 float64 이다.
np.ones(shape, dtype, order)
np.empty(shape, dtype)
zero랑 다르게 메모리 초기화를 아직 하지 않은 상태로 생성
something_like
ndarray의 shape만큼의 크기를 가진 1,0 또는 empty array 반환
np.identity(n, dtype)
단위행렬 반환
기본은 float
np.eye(n, m, k)
대각 행렬 생성, 시작지점 k
np.diag(matrix, k)
대각 행렬의 값을 추출
np.random.uniform(0,1,10) 균등분포
np.random.normal(0,1,10) 정규분포
test_array = np.arange(1,11)
test_array.sum(axis, dtype)
모든 element의 합 구함
axis
operation function의 dimension 축, 0부터 시작
sum 말고도 mean&std 가 존재.
concatenate
numpy array를 합치는 함수
vstack, hstack (vertical, horizental)
np.concatenate((a,b), axis)
array간의 기본적인 사칙연산 지원(shape이 동일할 경우) 같은 위치의 원소끼리 사칙연산됨
dot product
array_1.dot(array_2)
array.transpose() or array.T
for loop < list comprehension < numpy 순으로 속도 가진다.
그 이뉴는 NumPy는 C로 구현되어있어 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamic typing을 포기했다.
대용량 계산에서는 가장 흔히 사용된다.
하지만 concatenate처럼 계산이 아닌, 할당에서는 연산 속도의 이점이 없다.
np.any(조건), np.all(조건)
무엇이라도 하나가 조건을 만족하면, 모든 요소가 조건을 만족하면
사칙연산처럼 대소비교 역시 배열의 크기가 동일하면 각각의 elements간 비교결과를 boolean type으로 반환한다.
부등호로 비교해도 되고, 여러개의 조건으로 비교를 한다 했을땐
np.logical_and
np.logical_not
np.logical_or 등을 사용할 수 있다.
np.where(조건, 참일 경우 반환값, 거짓일 경우 반환값)
np.isnan, np.isfinite
np.argmax(matrix, axis), np.argmin(matrix, axis)
array 내의 최댓값 또는 최솟값의 index 반환
axis를 추가해주면 axis 별로 최댓값, 최소값의 index 반환
boolean index
condition = test_array < 3
test_array[condition] 이면 조건이 true인 index의 element만 추출한다.
fancy index
Numpy는 array를 index value로 사용해서 값을 추출한다.
a = np.array

b의 값을 인덱스로 삼아 새로운 array를 생성하는 것을 확인할 수 있다.
matrix도 a[b,c]의 형태로 사용 가능하다. (b,c)를 index로 사용
numpy data I/O
np.loadtxt()
np.astype(int)
np.savetxt('file_name', a_int, delimiter=",") => csv 로 저장
2-1 퀴즈
cammel case, snake case, pascal case..
java, spring 으로 프로젝트를 진행할 떄에는 cammelcase를 사용했지만, python으로 돌아온 이상 snake case를 다시 애용하게 될 것 같다.
하지만 Classname은 pascal case라는, 첫글자에 대문자, 띄어쓰기 부분에 대문자를 사용하는것을 잊으면 안될 것 같다.
NameError는 정의되지 않은 이름을 지정할때 하는것이고,
csv.reader의 delimiter 옵션은 쉼표가 아닌 다른 구분자를 사용할 때 설정
0차원 스칼라
1차원 벡터
2차원 matrix
n차원 n-tensor
np.zeros
어.... 이문제는 뭐지?
4y + 3인데 이상하네... 오타가 있는것 같다.

퀴즈 4 해결

베이즈 정리에 대한 개념 잘 알기
'Diary > TIL' 카테고리의 다른 글
| 2024-06-11) 토익 준비 (0) | 2024.06.11 |
|---|---|
| AI 와 관련된 유우명 유튜브들 (0) | 2024.06.07 |
| 2024-05-31) 인공지능 기초 다지기 2-4,5강 (0) | 2024.05.31 |
| 2024-05-29) 기술 면접 준비 (0) | 2024.05.29 |
| 2024-05-28) 기술 면접 공부 (0) | 2024.05.28 |

